Yüksek Trafikli Sistemlerde PostgreSQL Performansını Artırmak: Neden UUID v7?
Modern yazılım mimarilerinde, özellikle mikroservis yapılarında benzersiz kimlik belirleyiciler (ID) için UUID kullanımı artık bir standart haline geldi. Ancak saniyede binlerce istek alan ödeme geçitleri gibi yüksek yüklü sistemlerde, geleneksel UUID v4 kullanımı beklenmedik bir performans darboğazına (bottleneck) yol açabiliyor. Bu yazımda, anlık 5000 ve üzeri transaction beklenen sistemlerde neden UUID v4'ten vazgeçip UUID v7'ye geçmemiz gerektiğini teknik detaylarıyla inceleyeceğiz.
UUID v4'ün Gizli Maliyeti: Random I/O Problemi
PostgreSQL'de bir Primary Key oluşturduğunuzda, sistem bu kolon için arka planda bir B-Tree indeks yapısı kurar. UUID v4 tamamen rastgele üretilen bir veri tipidir. Bu rastgelelik, her yeni kayıt (INSERT) işleminde veritabanının indeks ağacının bambaşka bir yaprağına erişmeye çalışmasına neden olur. Saniyede 5000 kayıt geldiğini düşünün; disk kafası sürekli farklı noktalara sıçramak zorunda kalır (Random I/O). Bu durum, disk IOPS değerlerinin tavan yapmasına ve veritabanı yanıt sürelerinin (latency) artmasına yol açar.
UUID v7: Hem Benzersiz Hem Sıralı
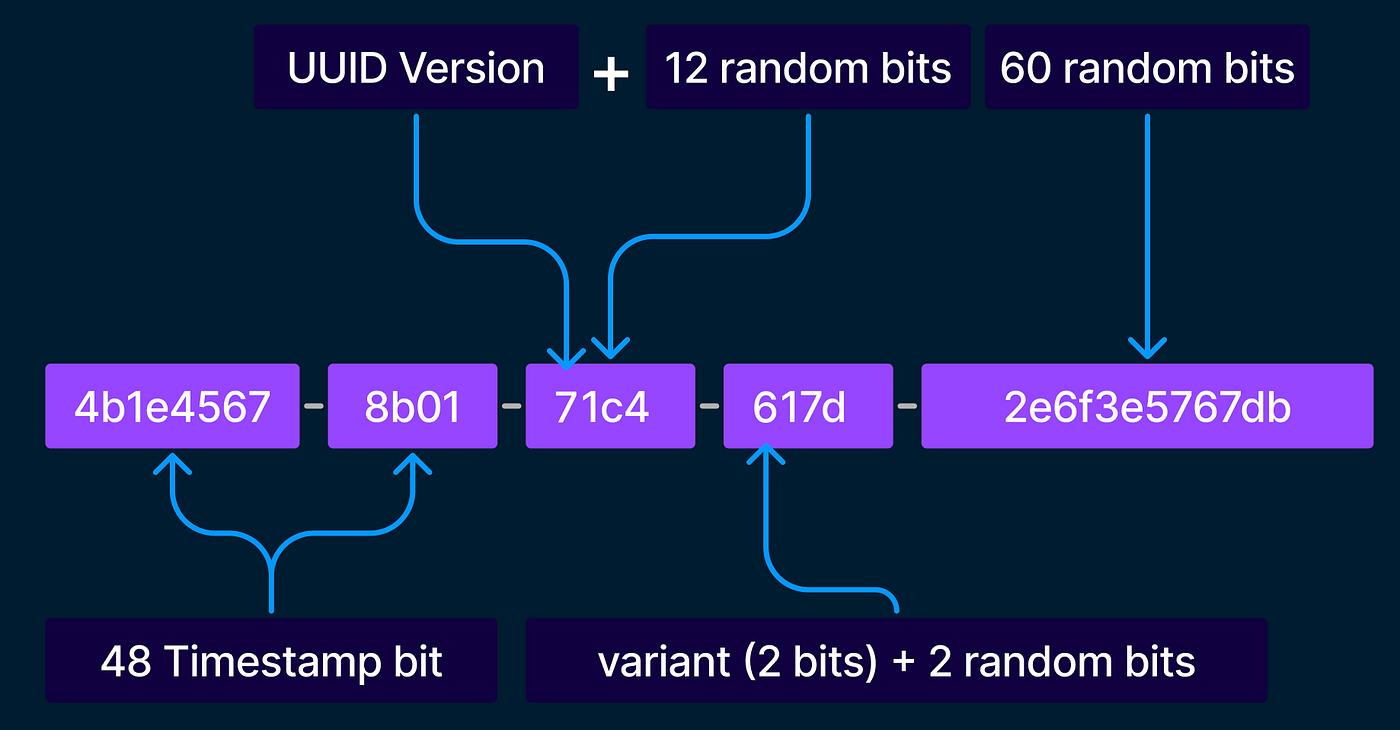
UUID v7, standart UUID'nin benzersizlik özelliğini korurken, ilk 48 bitinde milisaniye hassasiyetinde bir zaman damgası (timestamp) barındırır. Bu küçük dokunuş, üretilen her yeni UUID'nin bir öncekinden daha büyük (sequential) olmasını sağlar. Bu sayede PostgreSQL, yeni kayıtları indeks ağacının her zaman en sonuna ekler. Teknik olarak bu durum, veritabanının "Sequential I/O" yapmasını sağlayarak yazma hızını katbekat artırır.
UUID v7 Geçişinin Teknik Avantajları
1. İndeks Fragmantasyonunun Önlenmesi: Rastgele UUID'ler indeks sayfalarında boşluklar (fragmentation) yaratır ve indeks dosyasının gereksiz şişmesine neden olur. UUID v7 ise sayfaları tam dolulukla doldurarak disk alanını optimize eder.
2. RAM ve Cache Dostu Yapı: PostgreSQL, yoğun yazma işlemlerinde indeksin en güncel kısımlarını RAM'de (Shared Buffers) tutmaya çalışır. UUID v7'de yazma işlemi hep aynı bölgeye yapıldığı için ilgili indeks sayfası sürekli RAM'de kalır (Cache Locality). v4'te ise sürekli "Page Swapping" yaşanır ve bu da CPU yükünü artırır.
3. Dağıtık Sistemlerde Güvenlik ve Uyumluluk: Otomatik artan (Identity/BigInt) ID'lerin aksine, UUID v7 dışarıdan tahmin edilemezdir. Bu da ödeme sistemlerinde işlem ID'lerinin brute-force ile bulunmasını engeller.
PostgreSQL Üzerinde UUID v7 Uygulaması
Eğer PostgreSQL 17 öncesi bir sürüm kullanıyorsanız, UUID v7 üretmek için PL/pgSQL tabanlı bir fonksiyon kullanmanız gerekir. İşte performans odaklı bir UUID v7 fonksiyonu ve tablo tanımı örneği:
CREATE EXTENSION IF NOT EXISTS pgcrypto; (yüklü değil ise yüklü olması gerekir.)
CREATE OR REPLACE FUNCTION public.generate_uuid_v7()
RETURNS uuid
LANGUAGE plpgsql
AS $function$
DECLARE
ms bigint;
b bytea;
u bytea;
v int;
BEGIN
-- Unix epoch milliseconds
ms := (extract(epoch from clock_timestamp()) * 1000)::bigint;
-- int8send(ms) => 8-byte big-endian; son 6 byte => 48-bit timestamp
b := int8send(ms);
u := substring(b from 3 for 6) || gen_random_bytes(10); -- toplam 16 byte
-- Set version (byte offset 6): xxxx -> 0111xxxx
v := get_byte(u, 6);
u := set_byte(u, 6, (v & 15) | 112); -- 0x70
-- Set variant RFC4122 (byte offset 8): xx -> 10xxxxxx
v := get_byte(u, 8);
u := set_byte(u, 8, (v & 63) | 128); -- 0x80
RETURN encode(u, 'hex')::uuid;
END;
$function$
;Sonuç
Anlık yüksek trafikli bir ödeme sistemi veya loglama altyapısı kuruyorsanız, veritabanı seçimi kadar verinin diske nasıl yazılacağını düşünmek de kritiktir. UUID v7, uygulama katmanında hiçbir karmaşıklık yaratmadan, sadece ID formatını değiştirerek veritabanı performansınızı %30 ile %50 arasında artırabilir. Unutmayın, en iyi kod en az disk I/O'su harcayan koddur.