Docker ile Ollama + Open WebUI Kurulumu
Windows (WSL2) Üzerinde Docker ile Ollama + Open WebUI Kurulumu (Yerel LLM Modelleri) Yerel (local) büyük dil modelleri (LLM) çalıştırmak, hem veri gizliliği hem de maliyet kontrolü açısından ciddi avantaj sağlar. Bu yaz...

Windows (WSL2) Üzerinde Docker ile Ollama + Open WebUI Kurulumu (Yerel LLM Modelleri)
Yerel (local) büyük dil modelleri (LLM) çalıştırmak, hem veri gizliliği hem de maliyet kontrolü açısından ciddi avantaj sağlar. Bu yazıda, Windows üzerinde Docker Desktop + WSL2 backend kullanarak:
-
Ollama (model çalıştırıcı/servis)
-
Open WebUI (tarayıcıdan ChatGPT benzeri arayüz)
kurulumunu, model indirme–çalıştırma örneklerini ve pratik sorun giderme adımlarını paylaşıyorum.
1) Kavramlar: Ollama, Model (Llama/Qwen/Gemma), Open WebUI
- Model (Llama, Qwen, Gemma, Mistral, DeepSeek): Eğitilmiş “zeka” (ağırlıklar/parametreler). Tek başına çalışmaz.
- Ollama: Modelleri yerelde çalıştıran servis. Model indirir, saklar, çalıştırır ve HTTP API açar.
- Open WebUI: Tarayıcı arayüzü. Model çalıştırmaz; Ollama’ya bağlanır, sohbet ve yönetim ekranı sağlar.
Özet: Model = beyin, Ollama = motor/servis, Open WebUI = arayüz.
2) Ön Koşullar (Windows + Docker Desktop + WSL2)
Docker Desktop’ın WSL2 backend ile çalıştığını doğrulamak için:
wsl -l -vÇıktıda docker-desktop için VERSION = 2 görüyorsanız doğru altyapıdasınız.
GPU-PV (opsiyonel ama performans için önemli)
GPU hızlandırma hedefliyorsanız WSL kernel güncellemesi:
wsl --update3) Ollama’yı Docker’da çalıştırma (WSL2 backend)
Ollama servisini 11434 portuyla ayağa kaldırın (modeller kalıcı olsun diye volume kullanıyoruz):
docker run -d --name ollama -p 11434:11434 -v ollama:/root/.ollama ollama/ollama(NVIDIA GPU ile denemek isterseniz):
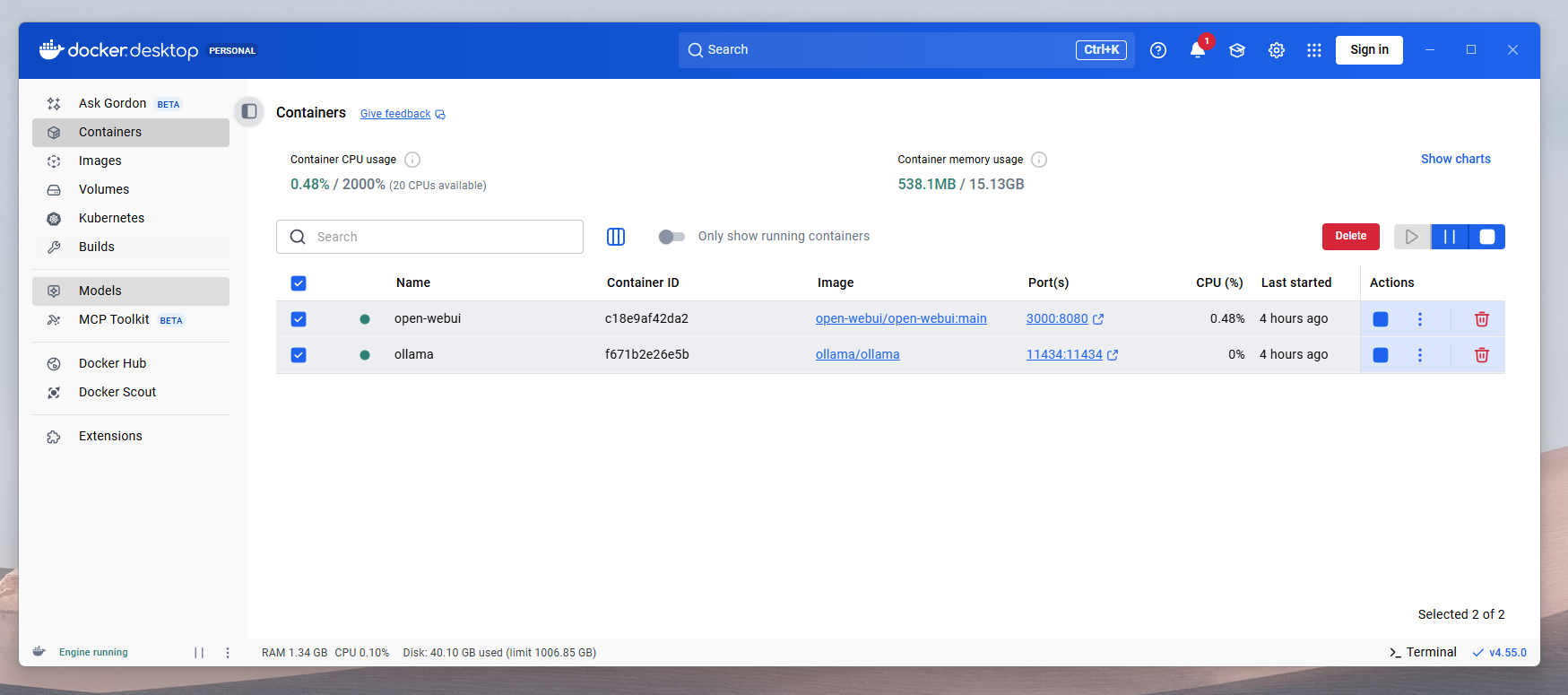
docker run -d --gpus=all --name ollama -p 11434:11434 -v ollama:/root/.ollama ollama/ollama4) Open WebUI’yi Docker’da çalıştırma
Open WebUI’yi 3000 portuyla başlatın:
docker run -d --name open-webui -p 3000:8080 -v open-webui:/app/backend/data ghcr.io/open-webui/open-webui:mainTarayıcıdan açın:
http://localhost:3000
5) İlk modeli çalıştırma ve popüler model indirme komutları
Önemli not: Open WebUI’de “Model” listesi boş görünüyorsa genelde sebep şudur: Ollama’da henüz model yoktur. Bu durumda /api/tags boş döner.
İlk model: Llama 3.2
Modeli indirip çalıştırmanın en hızlı yolu:
docker exec -it ollama ollama run llama3.2Popüler modelleri indirme (örnekler)
docker exec -it ollama ollama pull qwen2.5:7b
docker exec -it ollama ollama pull qwen2.5-coder:7b
docker exec -it ollama ollama pull gemma2:9b
docker exec -it ollama ollama pull mistral-nemo:12b
docker exec -it ollama ollama pull deepseek-r1:7bKurulu modelleri listeleme
docker exec -it ollama ollama listAPI üzerinden kontrol (model var mı?)
curl http://localhost:11434/api/tagsEğer çıktı "models": [] ise henüz model indirilmemiştir. Bir ollama pull veya ollama run çalıştırdıktan sonra liste dolacaktır.
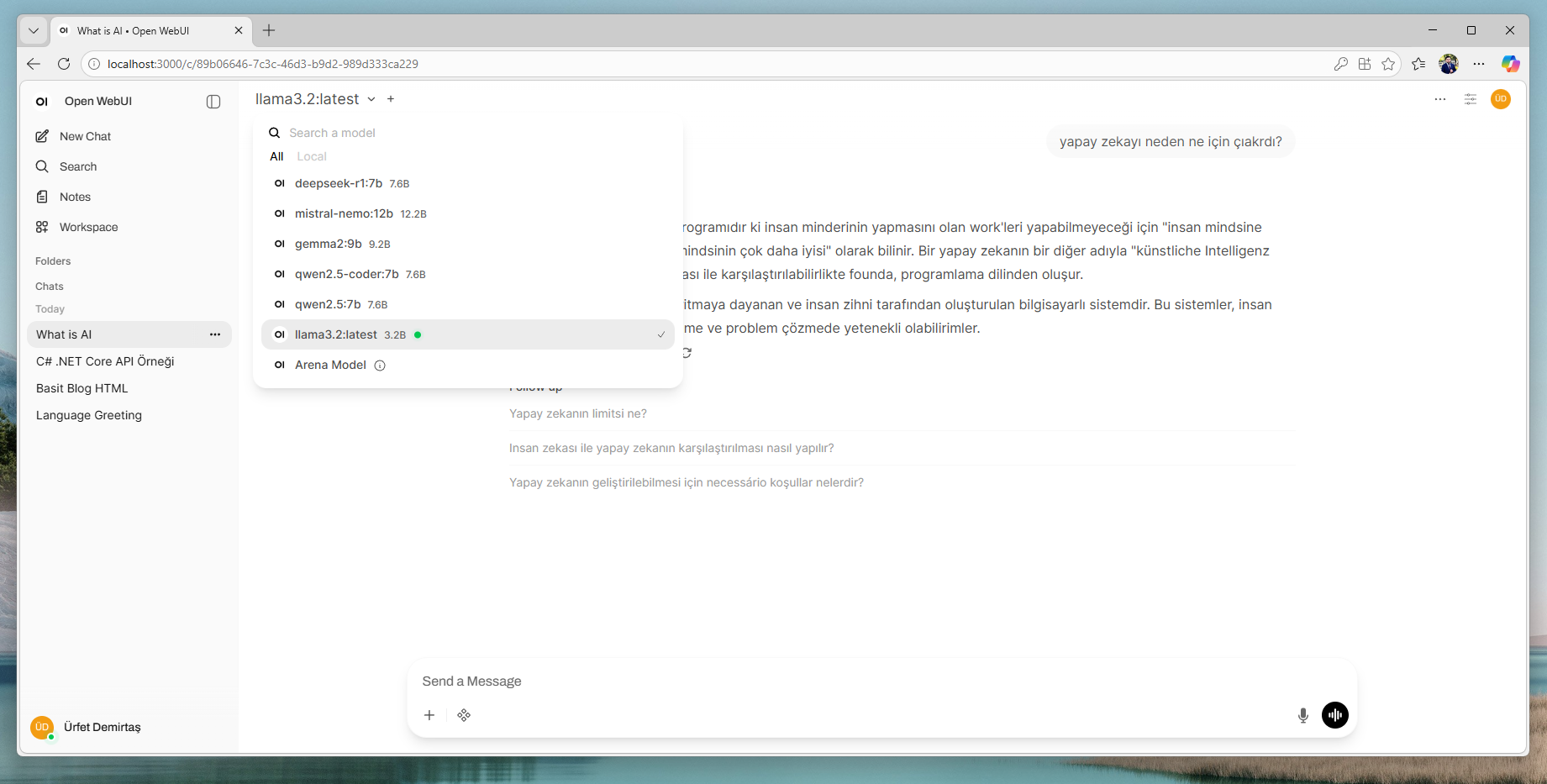
6) Open WebUI’de kullanım ipuçları
- Open WebUI’de yeni sohbet başlatın ve model seçin (ör.
llama3.2,qwen2.5:7b). - Teknik servis yanıtları gibi tekrar eden işler için “System Prompt / Preset” oluşturun.
Örnek: Teknik Servis Asistanı (System Prompt fikri)
- Kısa ve net yaz.
- Adım adım çözüm öner.
- Gerekirse menü yolunu/komutu ver.
- Varsayım yapıyorsan belirt.
7) Sık sorunlar ve hızlı çözümler
Sorun: Open WebUI’de model listesi boş
- Muhtemel neden: Ollama’da model yok.
- Çözüm:
docker exec -it ollama ollama run llama3.2veyaollama pullile model indirin. - Kontrol:
curl http://localhost:11434/api/tags
Sorun: Disk hızlı doluyor
Modeller GB seviyesinde yer kaplar. Kullanmadığınız modeli silebilirsiniz:
docker exec -it ollama ollama rm qwen2.5:7b8) Kısa model seçimi rehberi
- Genel kullanım (hız/denge): 7B sınıfı (ör.
qwen2.5:7b) - Kod odaklı:
qwen2.5-coder:7b - Az kaynak + hızlı yanıt:
llama3.2gibi 3B sınıfı modeller - Daha güçlü muhakeme: 12B+ (ör.
mistral-nemo:12b) ancak RAM/VRAM ihtiyacı artar
Sonuç
Bu kurulumla Windows üzerinde Docker Desktop (WSL2) kullanarak:
- Ollama ile modelleri yerelde çalıştırabilir,
- Open WebUI ile tarayıcıdan ChatGPT benzeri deneyim yaşayabilir,
- Llama/Qwen/Gemma/Mistral/DeepSeek gibi modelleri ihtiyacınıza göre indirip yönetebilirsiniz.