PostgreSQL'de Partitioning Stratejileri: Milyonlarca Satırlık Tabloları Nasıl Yönetmeliyiz?
Büyük ölçekli sistemler inşa ederken (özellikle 50.000+ aktif kullanıcı hedefliyorsanız), veritabanı performansınızın zamanla doğrusal olmayan bir şekilde düştüğünü fark edersiniz. Milyarlarca satıra ulaşan bir Orders veya Logs tablosunda basit bir SELECT sorgusu bile, indekslere rağmen ağırlaşmaya başlar. İşte bu noktada devreye Table Partitioning girer.
Table Partitioning Nedir? Neden İhtiyacımız Var?
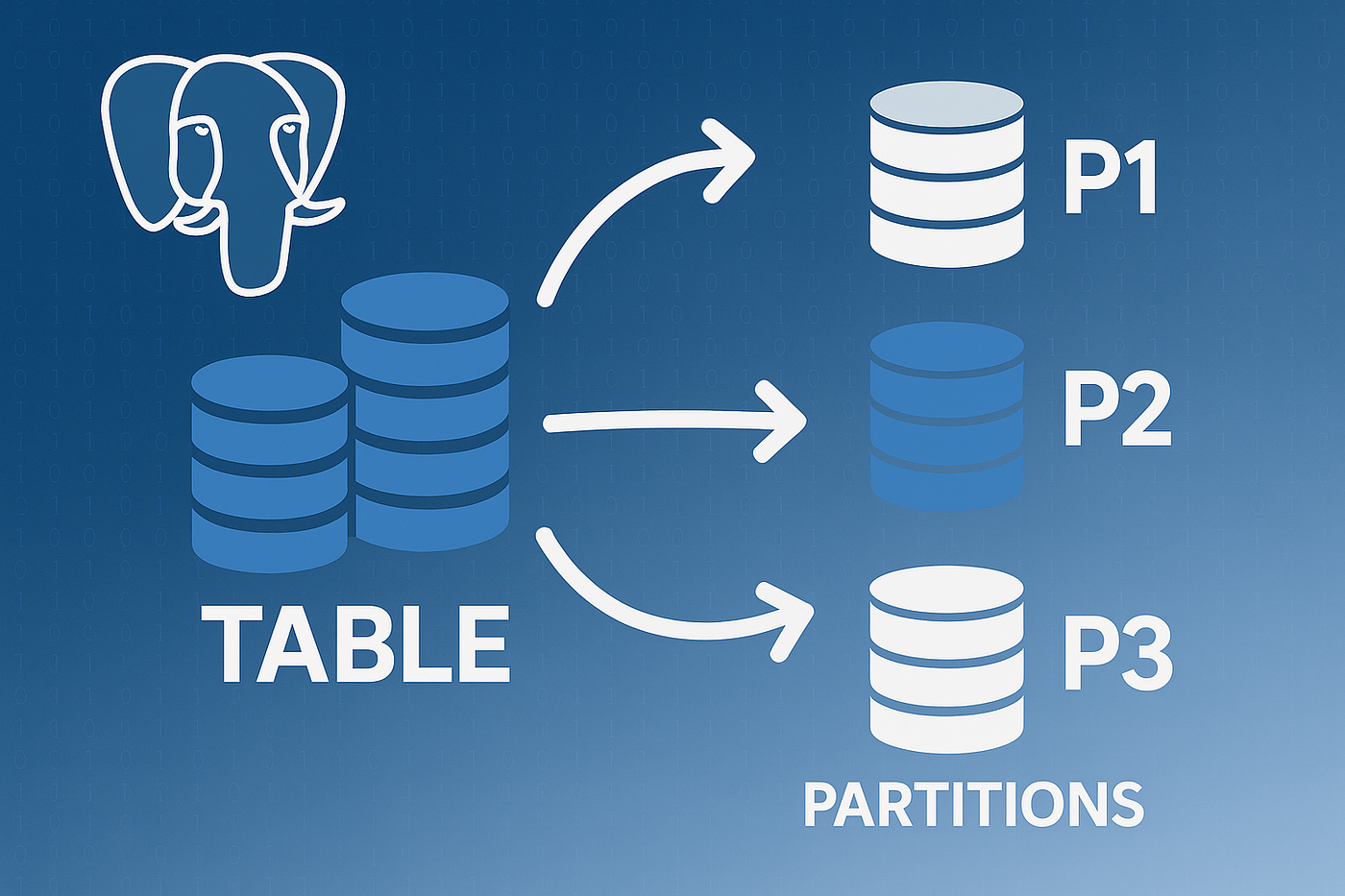
Partitioning, devasa bir tabloyu mantıksal olarak aynı kalsa da fiziksel olarak daha küçük, yönetilebilir parçalara (partition) bölme işlemidir.
Neden yapıyoruz?
-
Query Pruning: PostgreSQL, sorgu geldiğinde sadece ilgili "parçaya" bakar. Diğer milyonlarca satırı görmezden gelir.
-
Maintenance: 1 TB'lık bir tabloya
VACUUMyapmak kabustur. Ancak 10 GB'lık parçalara bölündüğünde bu işlem çok daha hızlı ve sorunsuz biter. -
Data Lifecycle: Eski verileri silmek için
DELETEkomutu yerine (ki bu çok maliyetlidir ve bloat yaratır), direkt ilgili parçayıDROPedebilirsiniz.
1. PostgreSQL'de Partitioning Türleri
PostgreSQL 10 ile gelen Declarative Partitioning sayesinde artık bu süreç çok daha standart. Temelde üç ana stratejimiz var:
A. Range Partitioning (Aralık Bazlı)
En yaygın kullanımdır. Genellikle created_at gibi zaman damgaları üzerinden yapılır.
-
Örnek: "2024-Ocak verileri bir tabloda, Şubat verileri başka tabloda olsun."
B. List Partitioning (Liste Bazlı)
Belirli bir anahtar değere göre bölme yapılır.
-
Örnek:
country_codekolonuna göre verileri 'TR', 'US', 'EU' şeklinde ayırmak.
C. Hash Partitioning (Karma Bazlı)
Eğer veriyi mantıksal bir gruba ayıramıyorsanız ama yükü eşit dağıtmak istiyorsanız kullanılır.
-
Örnek:
user_idüzerinden hash alarak yükü 10 farklı parçaya yaymak.
2. Uygulama: Range Partitioning Senaryosu
Diyelim ki bir Payment Gateway projesi geliştiriyoruz ve transactions tablomuz çok büyüdü.
-- Ana tabloyu (Parent) oluşturuyoruz
CREATE TABLE transactions (
id UUID DEFAULT uuid_generate_v7(),
amount DECIMAL(18,2),
created_at TIMESTAMP NOT NULL,
status TEXT
) PARTITION BY RANGE (created_at);
-- 2026 Ocak ayı için partition oluşturma
CREATE TABLE transactions_2026_01 PARTITION OF transactions
FOR VALUES FROM ('2026-01-01') TO ('2026-02-01');
-- 2026 Şubat ayı için partition oluşturma
CREATE TABLE transactions_2026_02 PARTITION OF transactions
FOR VALUES FROM ('2026-02-01') TO ('2026-03-01');Bu yapı sayesinde, WHERE created_at BETWEEN '2026-01-15' AND '2026-01-20' dediğinizde, PostgreSQL sadece transactions_2026_01 tablosuna bakacaktır.
3. Kritik İpuçları ve Dikkat Edilmesi Gerekenler
-
Partition Key Seçimi: Partition yaptığınız kolon mutlaka sorgularınızın
WHEREkoşulunda olmalıdır. Aksi takdirde PostgreSQL tüm partition'ları tarar (Sequential Scan) ve performans kazanımı elde edemezsiniz. -
Global Indexes: PostgreSQL'de tüm partition'ları kapsayan "Global Index" yoktur. Her partition'ın kendi indeksi olur. Primary Key oluştururken partition anahtarını da (örneğin
created_at) PK'ya dahil etmeniz gerekir. -
Default Partition: Tanımladığınız aralıkların dışındaki veriler için mutlaka bir
DEFAULTpartition oluşturun; aksi halde veri ekleme sırasında hata alırsınız.
Sonuç
Milyonluk trafikleri yöneten bir Software Architect için partitioning, bir tercih değil zorunluluktur. Doğru stratejiyle kurgulanan bir veritabanı, sadece bugünün değil, 5 yıl sonrasının yükünü de taşıyabilir.